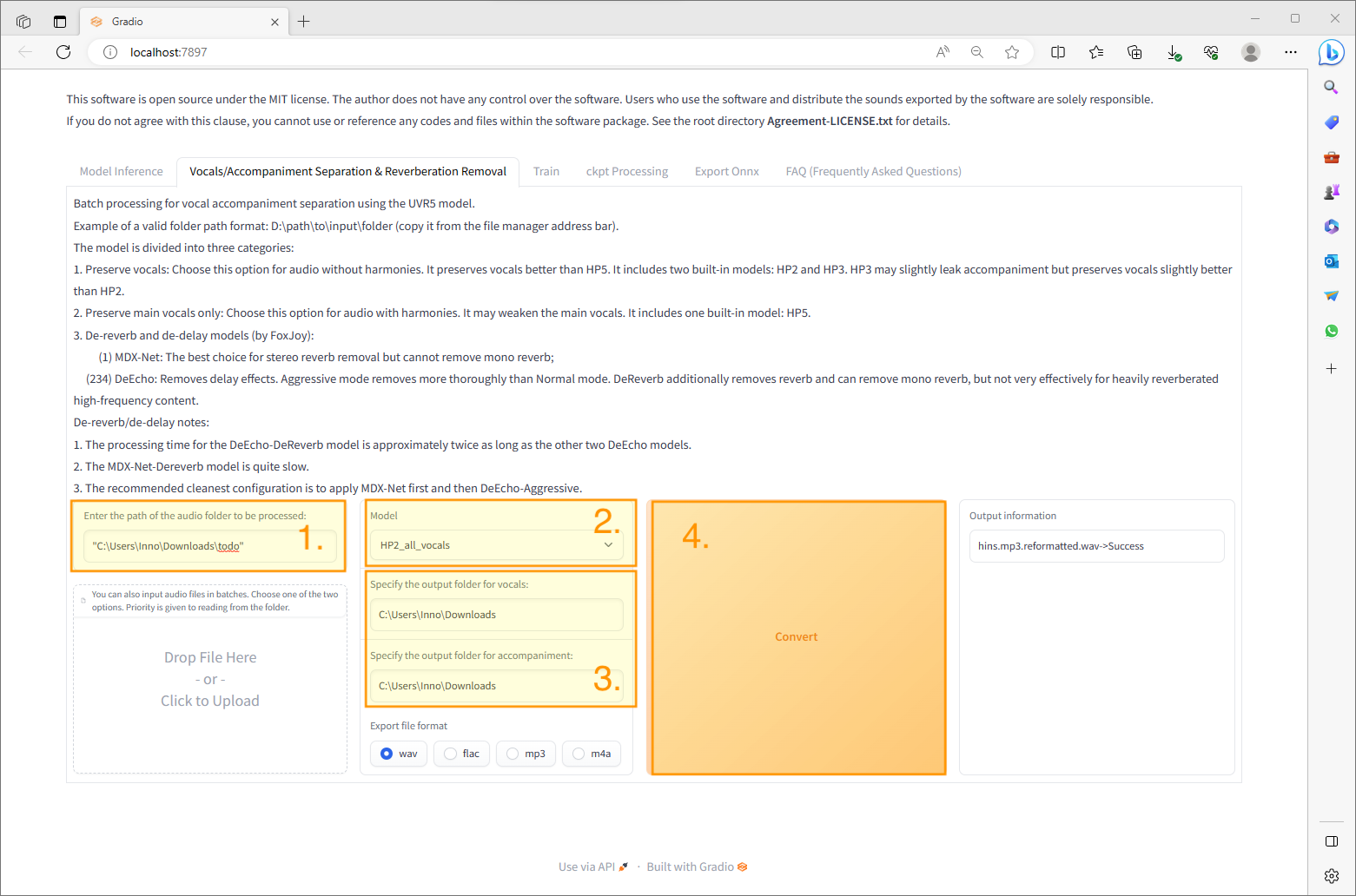
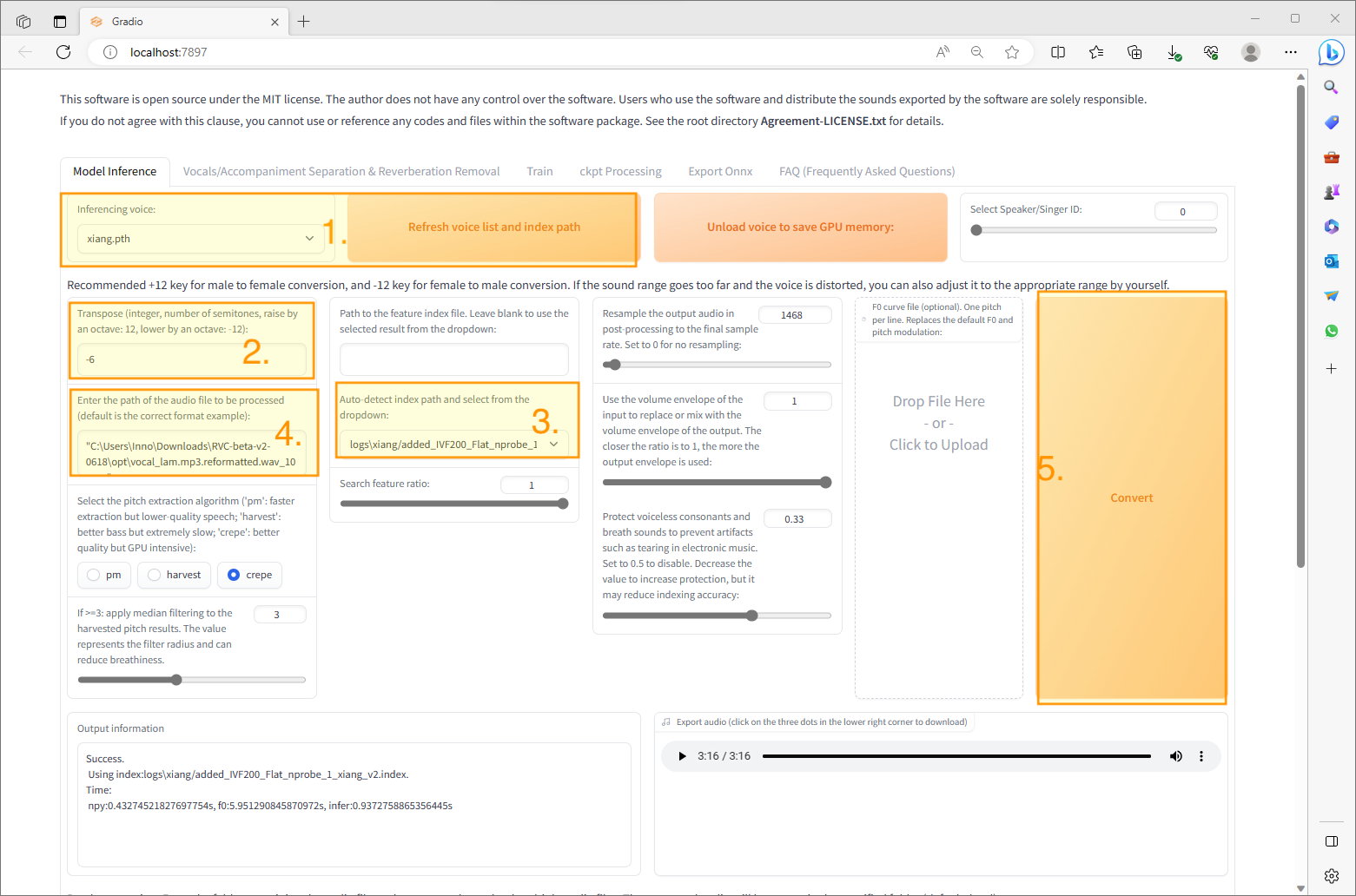
female futuristic cyberpunk 2077, ((daytime)) sci-fi, vibrant colours, neon colours, dyed hair, bright eyes, cybernetic implants, beautiful, portrait, presentation, Masterpiece, Studio Quality, 4k, solo, solemn expression, neutral expression, symmetrical face, futuristic background, camera front facing, concept art, elegant, highly detailed, intricate, sharp focus, (((medium shot))), (centered image compos1ition), head center, (professionally color graded), trending on instagram, trending on tumblr, hdr 4k, 8k, visible face, clear face, ((bright soft diffused light)), full head, (((head centered in frame))), volumetric fog, professional soft lighting